fadi
FADI - Ingest, store and analyse big data flows
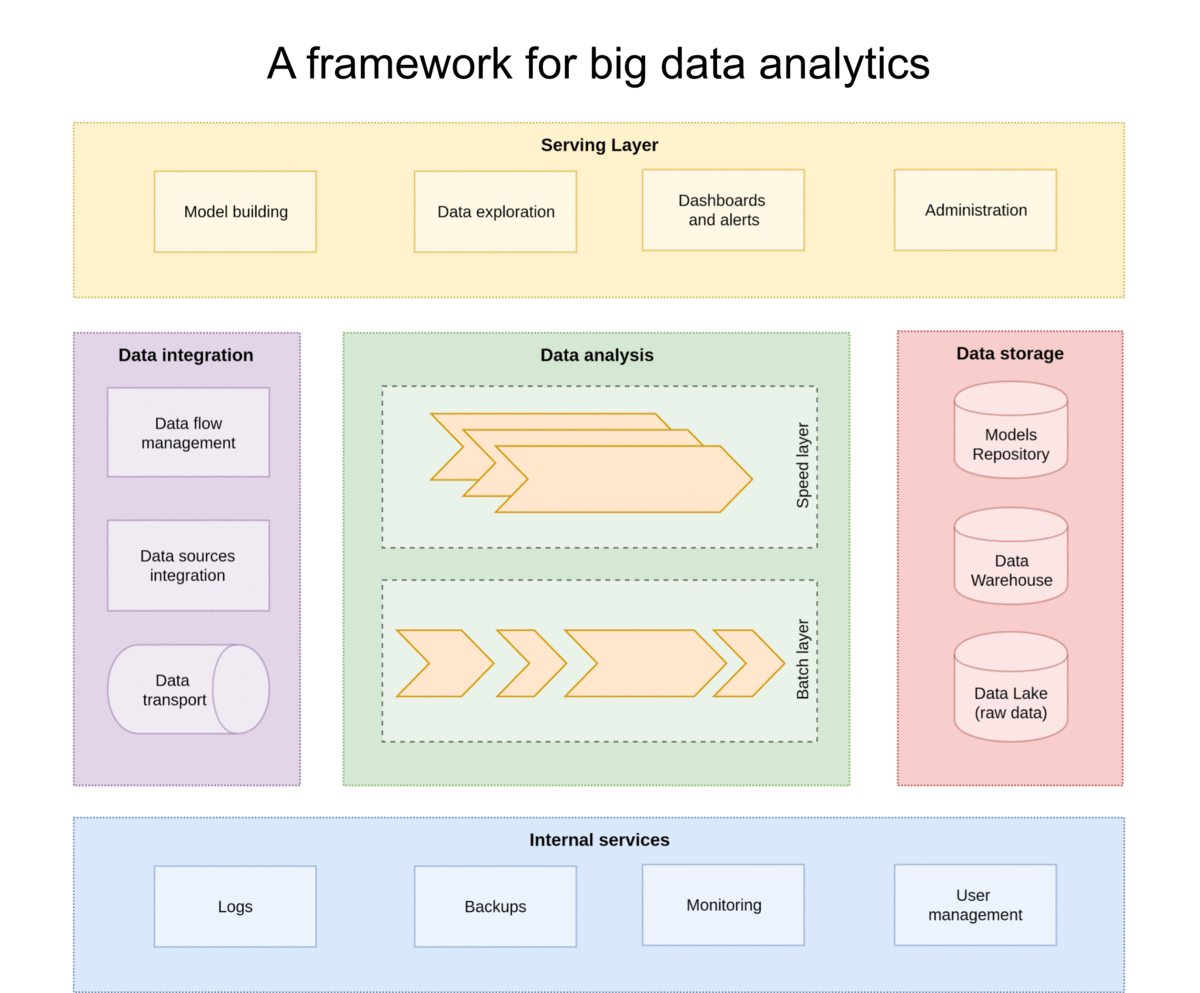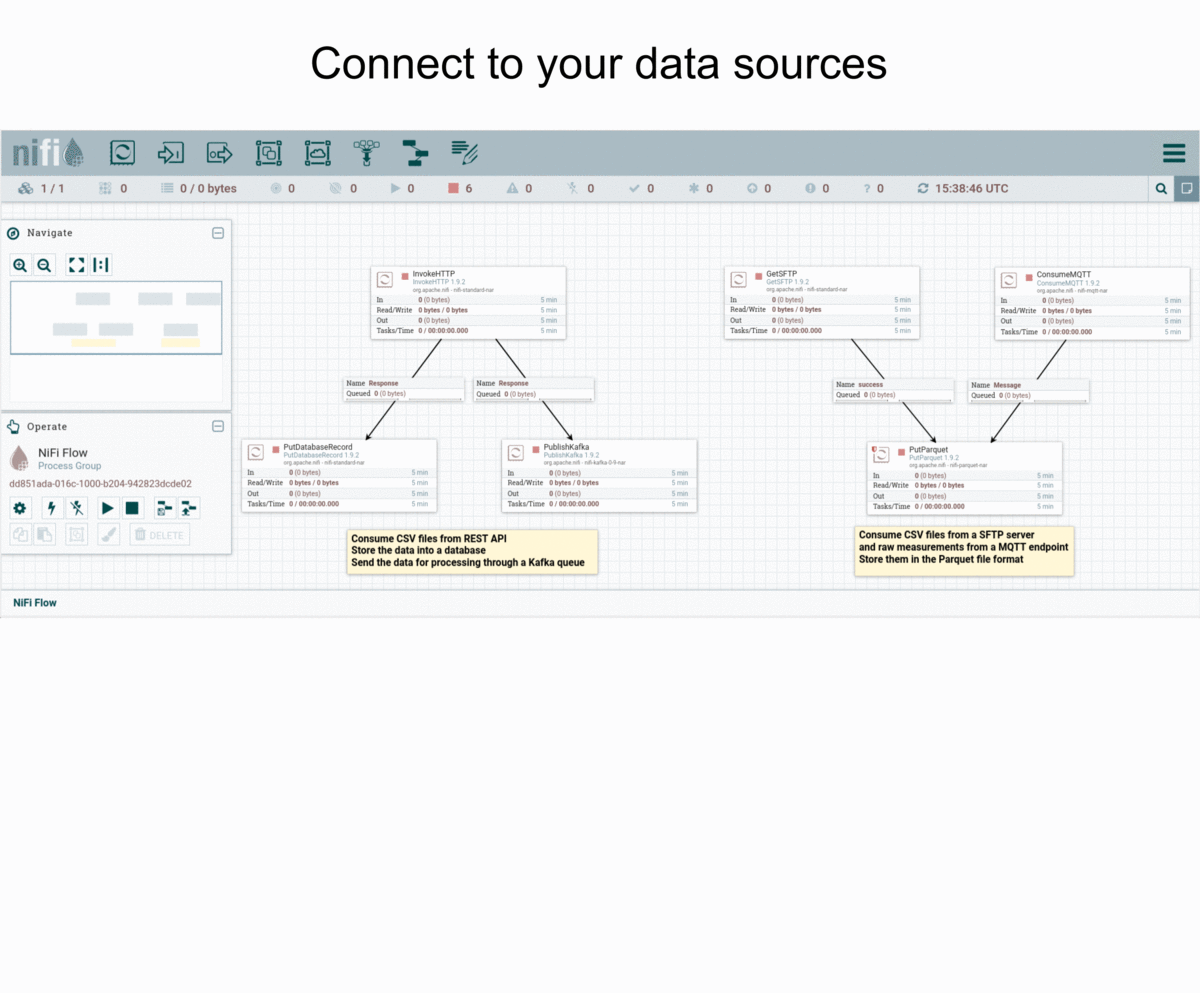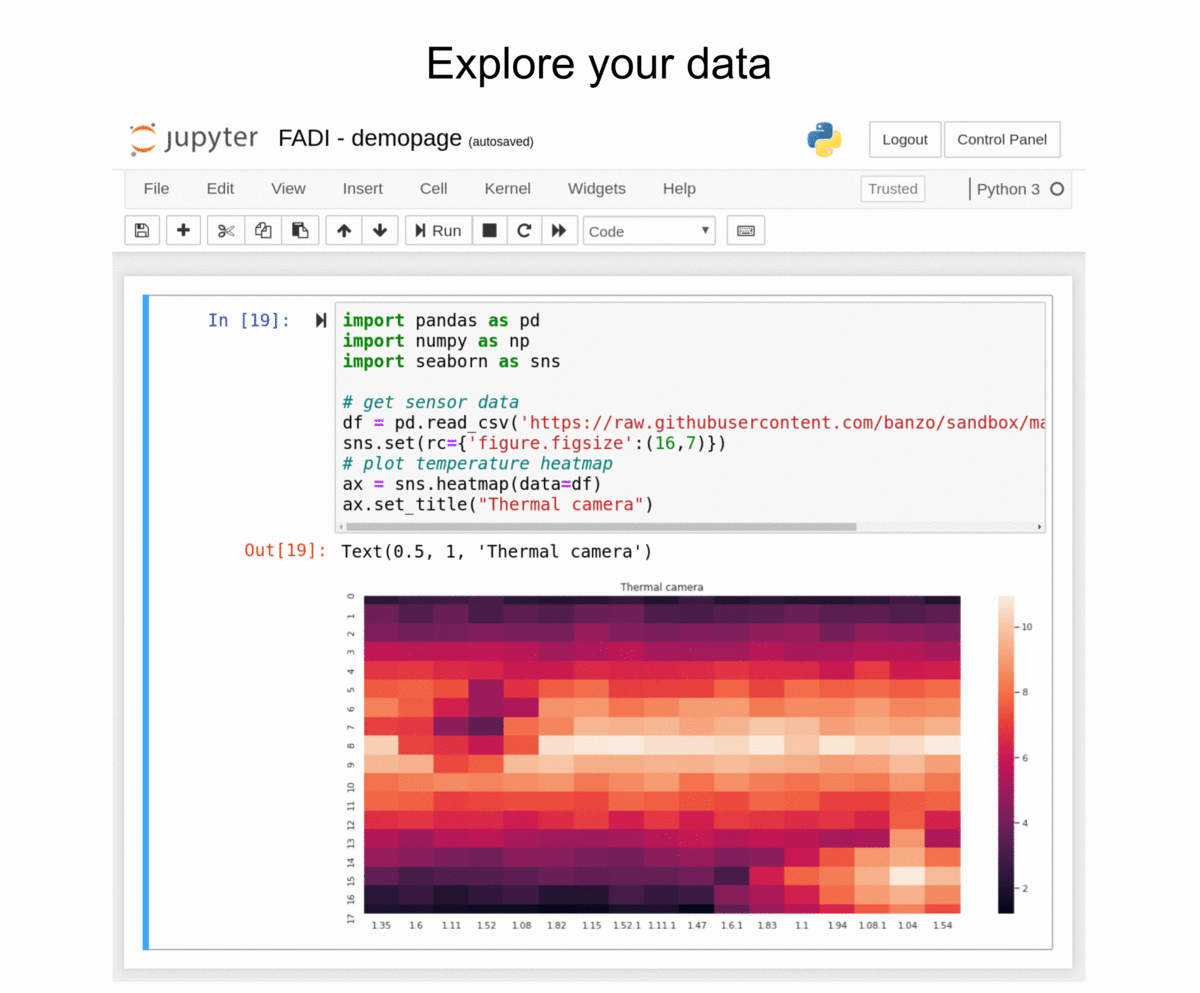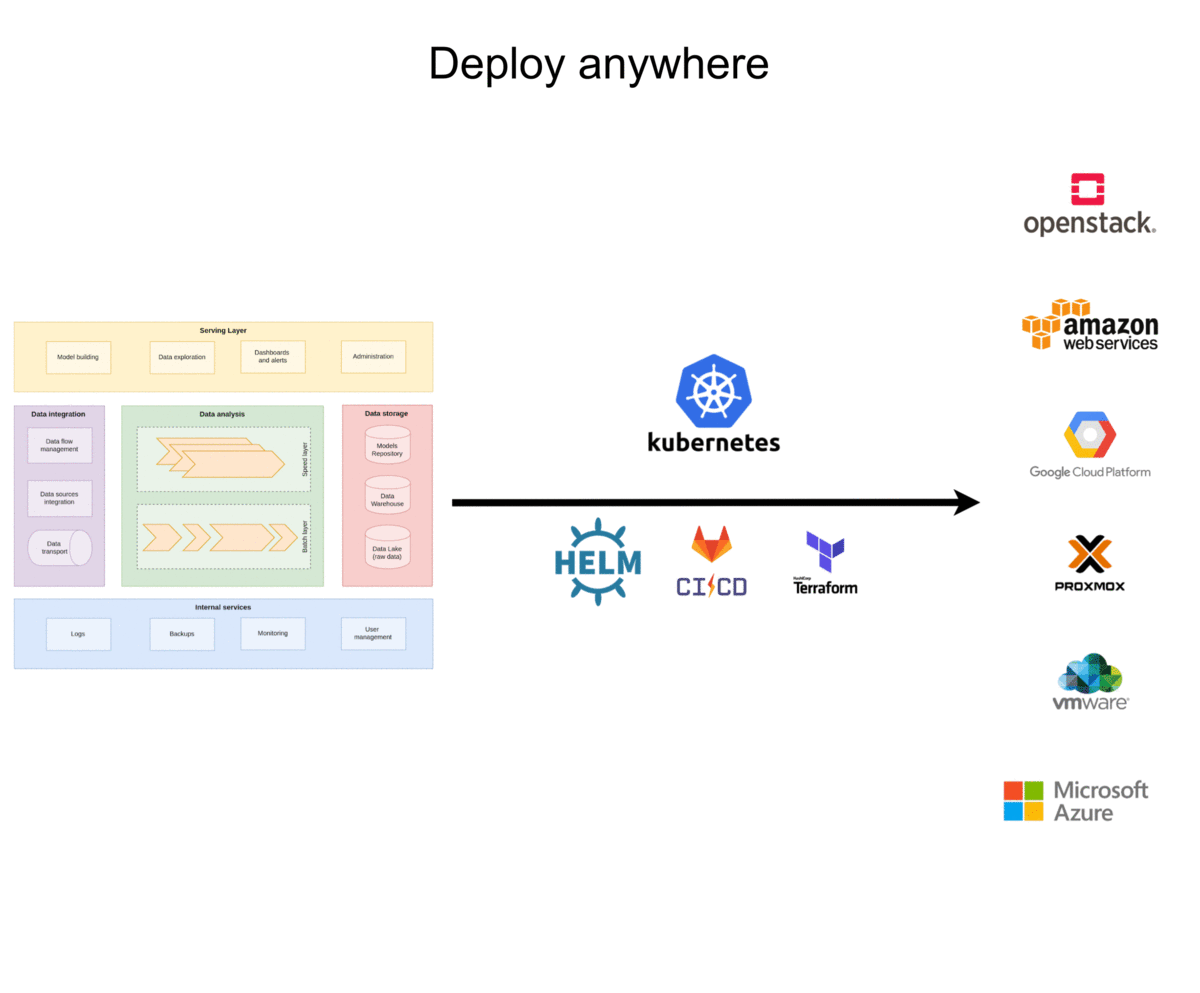
FADI - A framework for big data analytics
![]()


\({\color{red}This \space project \space is \space not \space maintained \space anymore.}\)
![]()
What is FADI?
The purpose of FADI is to provide a straightforward way to deploy integrated and modular Big Data systems to various infrastructures (private and public clouds). FADI relies on the Kubernetes container orchestration engine for portability and scalability.
Quick start
You can find a more detailed explanation of FADI in the presentation slideshow and in the documentation section
FADI Helm Chart

This repository contains the Helm chart to install FADI in a Kubernetes cluster.
Support
In case you encounter an issue with FADI, have a feature request or any other question, feel free to open an issue.
Feel also free to check out the FAQ!
About

You can find out more about FADI on the CETIC website
License
